1. Getting Started with vuSmartMaps™
3. Console
5. Configuration
6. Data Management
9. Monitoring and Managing vuSmartMaps™
![]()
ContextStream, also sometimes referred to as Data Streams, are an integral part of the data flow process within the vuSmartMaps™ platform. ContextStream is a comprehensive data processing engine that receives the data, processes, enriches, massages, and transforms the data, and then writes it into a data store for the end user’s consumption. It is highly scalable, capable of handling multi-million records, and engineered to ensure there are no single points of failure and no data loss.
![]()
Data pipelines are constructed with multiple data transformation plugins such as session plugin, data manipulation, ISO-8583, etc. These pipelines are highly versatile, enabling users to transform and enrich data in various ways to suit their specific needs. The primary function of Data pipelines is to read data from an input stream, process it, and then send it to another Output Stream/database.
![]()
Ensure data acquisition is functioning correctly and data is being ingested into vuSmartMaps from the target system. This may require verifying that the respective O11ySource is configured correctly.
![]()
![]()
ContextStreams within vuSmartMaps serve as sophisticated orchestrators that not only transport raw data but also transform it with rich context, making it meaningful for the observability journey. The process of contextualization involves the enhancement of raw data by adding metadata, categorizing information, and ensuring it aligns with the specific requirements of observability.
![]()
Raw data, in its unstructured form, often lacks the necessary context for effective analysis. Contextualization bridges this gap by adding layers of information that provide insights into the who, what, when, where, and why of each data point. For example, associating a transaction with a specific user, timestamp, and geographic location. By contextualizing data, organizations can unlock a deeper understanding of their systems, transactions, and user interactions.
![]()
![]()
![]()
The data is collected from the target system through Observability Sources. The data then undergoes a significant transformation during the data processing phase, thanks to ContextStreams. This phase occurs in the distinct sections: I/O Streams, Data Pipeline, and DataStore Connectors, with each having a unique role in processing data. Additionally, the Flows tab gives a display of the data processing journey.
![]()
![]()
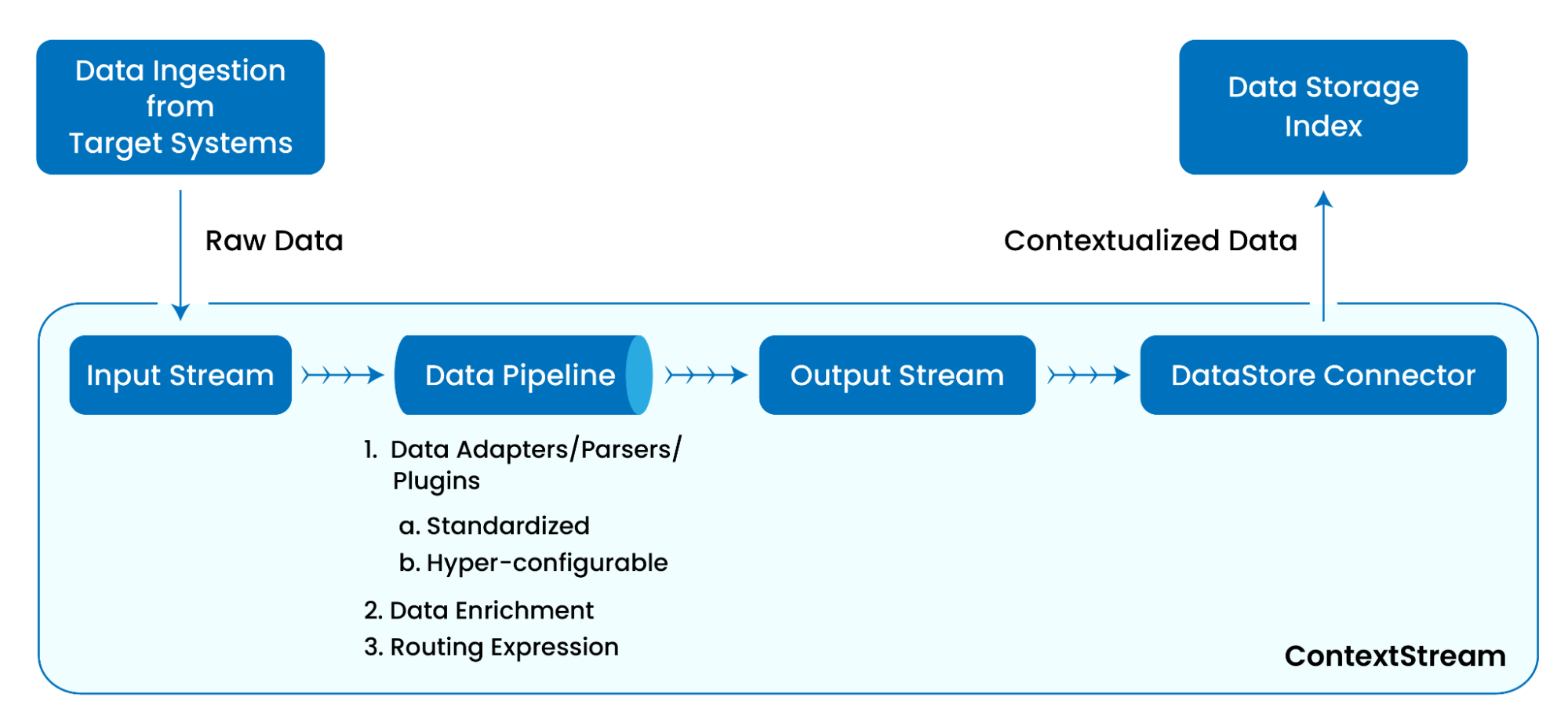
To visualize the journey of data through ContextStreams, consider the following diagrammatic overview:
![]()
![]()
This diagram provides a visual narrative of how ContextStreams orchestrate the entire journey of raw data, transforming it into a valuable asset for comprehensive observability. Now Let’s look into the live data pipeline, showcasing a real-world example of the contextualization of raw logs from a typical Internet and mobile banking application through a sophisticated ensemble of data adapters and parsers.
![]()
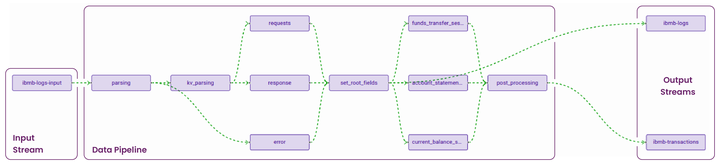
![]()
Debugging Feature: I/O Streams offer a “Preview” option, enabling users to verify and download streamed data, facilitating quick debugging. Data pipelines provide three debug options — For Published pipeline, Draft pipeline, and at the Block level—allowing users to inspect the output at different stages, aiding in effective debugging and diagnosis of data processing workflows.
![]()
In the subsequent sections of this user guide, we will explore ContextStreams in more detail, including their configuration, key functionalities, and how they contribute to an enhanced data flow experience.
![]()
In the data transformation process within vuSmartMaps, a diverse set of plugins empowers users to shape and enrich the data with Contextstreams. These plugins play a pivotal role in tailoring the data flow to specific needs. Explore the following supported plugins to understand their functionalities and discover how they can enhance your data processing experience.
![]()
![]()
These plugins collectively offer a versatile toolkit for users to shape and transform their ContextStreams according to specific needs and scenarios, enhancing the flexibility and efficiency of data processing within the vuSmartMaps platform. For more specific details on each plugin and its usage, refer to the vuSmartMaps Plugin Documentation.
![]()
vuSmartMaps provides two distinct methods for data processing to cater to diverse user requirements. The first method involves seamless data contextualization using standard O11ySources. The second approach allows users to create ContextStreams based on their unique requirements.
![]()
Opting for data ingestion through standard O11ySources provides a seamless and automated data contextualization experience. The system takes care of creating the essential components — I/O streams, data pipelines, and DataStore Connectors — specific to the chosen O11ySource. Enabling the O11ySource triggers the automatic creation of corresponding I/O Streams, initialization of the necessary Data Pipeline, and establishment of required DataStore Connectors. This automated workflow ensures efficient organization, transformation, and secure storage of data, eliminating the need for manual intervention. If required, you can enhance the data processing and contextualization logic by modifying the data pipeline configuration.
![]()
Refer to the O11ySources user guide to understand the specific workflow for O11ySources. Detailed instructions for managing ContextStreams can be found in subsequent sections of this user guide.
![]()
The second approach involves creating a configurable ContextStream tailored to specific requirements, requiring users to meticulously analyze the entire data flow journey and consider all touchpoints. The creation process involves defining the input stream, designing the data pipeline with necessary intermediate blocks for processing (each containing multiple plugins), and establishing an output stream. Additionally, DataStore Connectors are created to forward processed data to storage. Before initiating this creation process, a thorough analysis is crucial to accurately identify the required blocks. Depending on processing requirements, the design of the pipeline, blocks, and plugins should be ready before moving on to creating the ContextStream on the platform. The steps for creating, debugging, and managing the ContextStreams are discussed in detail in subsequent sections of this user guide.
![]()
The ContextStreams page can be accessed from the platform left navigation menu by navigating to Data Ingestion > ContextStreams.
![]()
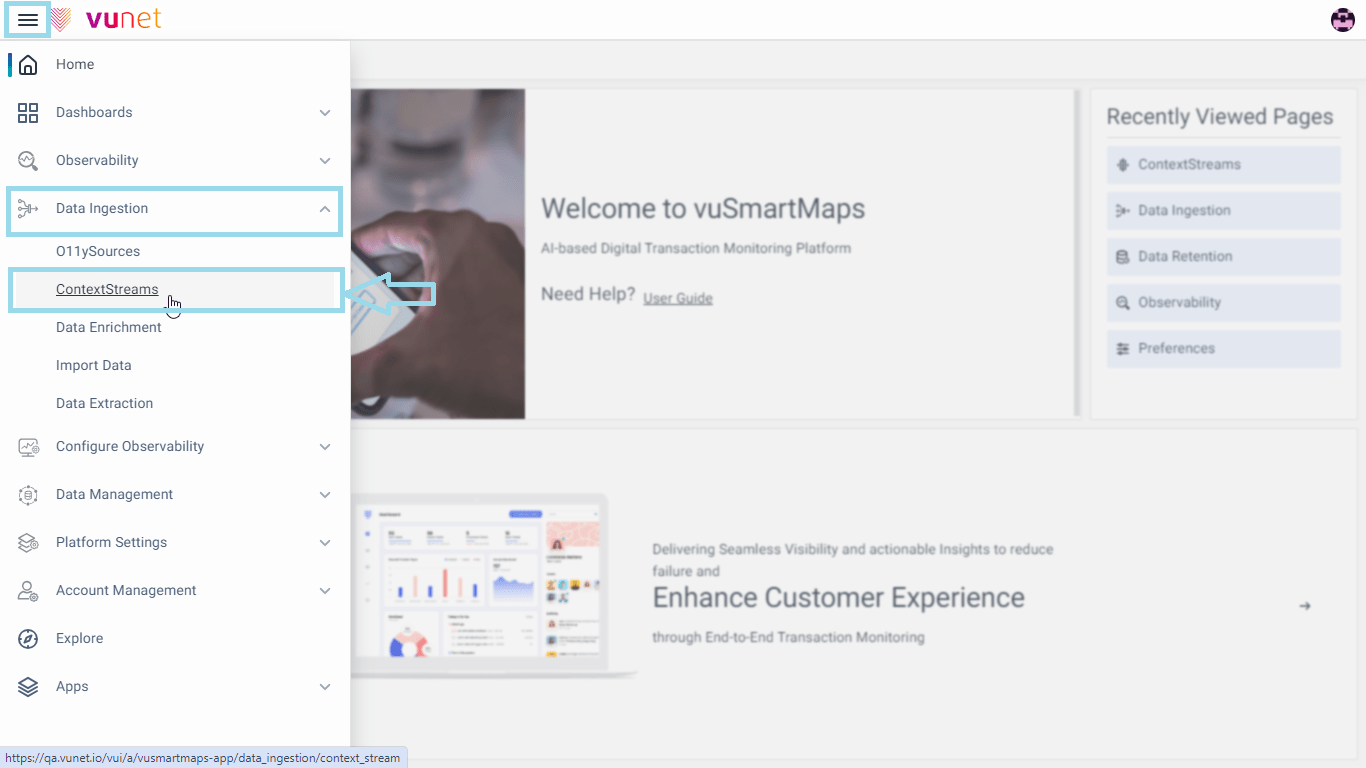
![]()
The ContextStreams landing page will look like this where you can create/configure the I/O streams, data pipelines, or DataStore Connectors with the different options.
![]()
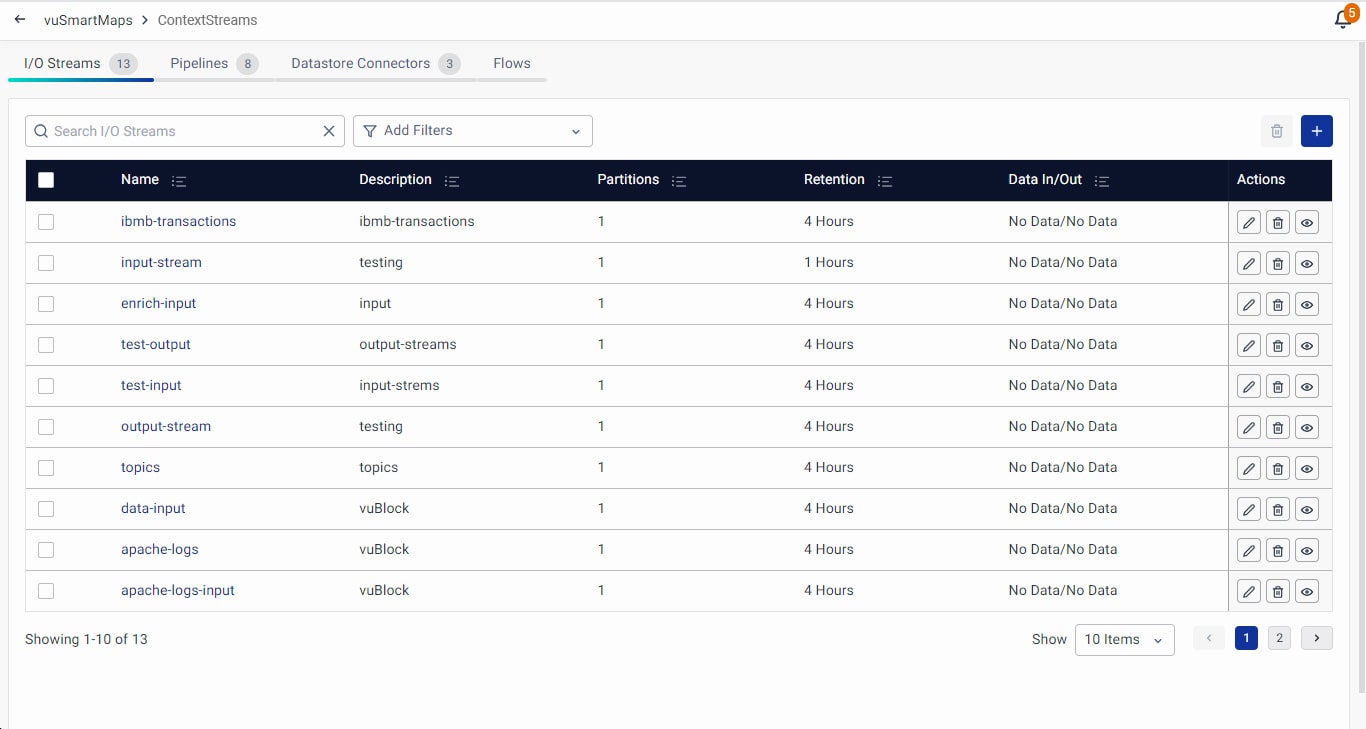
![]()
The user interface of the ContextStream section is composed of four primary tabs (I/O Streams, Data Pipeline, DataStore Connectors, Flows), each designed to facilitate specific actions and configurations, enhancing your ability to harness the full potential of ContextStream management.
![]()
Please refer to the subsequent sections for creating, debugging, and managing the ContextStreams.
![]()






