


As a business journey observability platform, a scalable and efficient data framework that caters to our unique set of real-time analytics requirements is critical to us. Moreso, with a recent explosion in telemetry data volumes, the cloud and infrastructure costs for observability solutions has significantly shot up by more than 100%. All this made it more paramount for us to recently embark on an ambitious journey to transform our data architecture to enhance our platform performance, scale and cost-effectiveness.Through extensive R&D, optimizations and benchmarking at scale, we are proud to unveil a major milestone: our HyperScale Data Store. This new data store framework is meticulously designed to efficiently handle vast datasets and data modeling in real-time along with optimized storage. HyperScale Data Store will drastically enhance our platform's capability to operate at a scale of terabytes/petabytes while providing a sweet spot in terms of reduced Total Cost of Ownership (TCO) to our customers by more than 30%.
Why does Datastore matter for an observability platform?
Before delving into the details of the new architecture, it is necessary to understand the critical role of the datastore in an observability platform and the considerations that went into completely revamping it.Here are a few complex and conflicting requirements from the datastore component in an observability platform.1. High Speed, High Volume Writes: The platform often deals with a high volume of events per second, ranging from 100,000 to 1 million. The writes are typically in append mode, requiring occasional updates2. Complex reads: Aggregation queries with multiple levels of grouping/bucketing are common to power real-time visibility using live dashboards and proactive alert notifications. The queries would often involve high cardinality fields. Since these reads power real dashboards and alerts, sub-seconds response time is expected.3. Data refresh time: The time taken for new data to start appearing in queries/searches should be low - any delay more than 30-45 seconds becomes prohibitive.4. Real-time data vs long-term data: The design had to address the needs of real-time and long-term data management. It has to handle
- frequent reads of recent data (span: few hours to days) - crucial for immediate observability
- store data for extended periods (span: days to years) - long-term analytics, postmortem analysis, and compliance requirements
The design balances and dual functionality are critical for storage efficiency, the ability to query long-term data and offering optional flexibility in response times for these extended data sets.5. Handling breadth of data types: The need to manage a diverse array of data types like metrics, traces, events and logs with a lot of variations in schema and structure6. Availability: Zero loss of data, availability exceeding 99.99% and cross-availability zones coupled with replication of data across data centers are becoming critical for data stores of observability platforms7. Data Access controls: Enforcing access controls to data based on roles at the data store table and record level is becoming necessary as the observability platform is now being leveraged for shift right scenarios business, support and partner teams across an enterprise.
Introducing VuNet’s HyperScale DataStore
With the above in context, at VuNet we have now moved to a whole new, composite architecture for data store. Based on columnar data architecture and a unique data management layer to cater to high-speed reads and writes.

Fig: HyperScale Data StoreThe core capabilities of the new data store layer include:
- High-speed writes: Achieving benchmarks of 1 Million events per second with a standard 8-core machine catering to 100K EPS for writes. New data ingested is designed to be query-ready within an average gap of less than 30 seconds.
- High-speed reads: Enabled by materialized views, the HyperScale data store provides sub-second loading of complex dashboards on real-time data. At the other end of the spectrum, it supports swift responses, typically in less than 10 seconds, for long-term data queries examining information spanning over one year and involving over 1 Billion records.
- Data pipeline integration: Integrates seamlessly with VuNet’s real-time data pipeline, enhancing write efficiency through bulk data pull mode.
- Built-in automatic schema evolution to adapt to observability data variability including optional fields and dynamic fields.
- User and user access policies at table levels and row levels with granular controls.
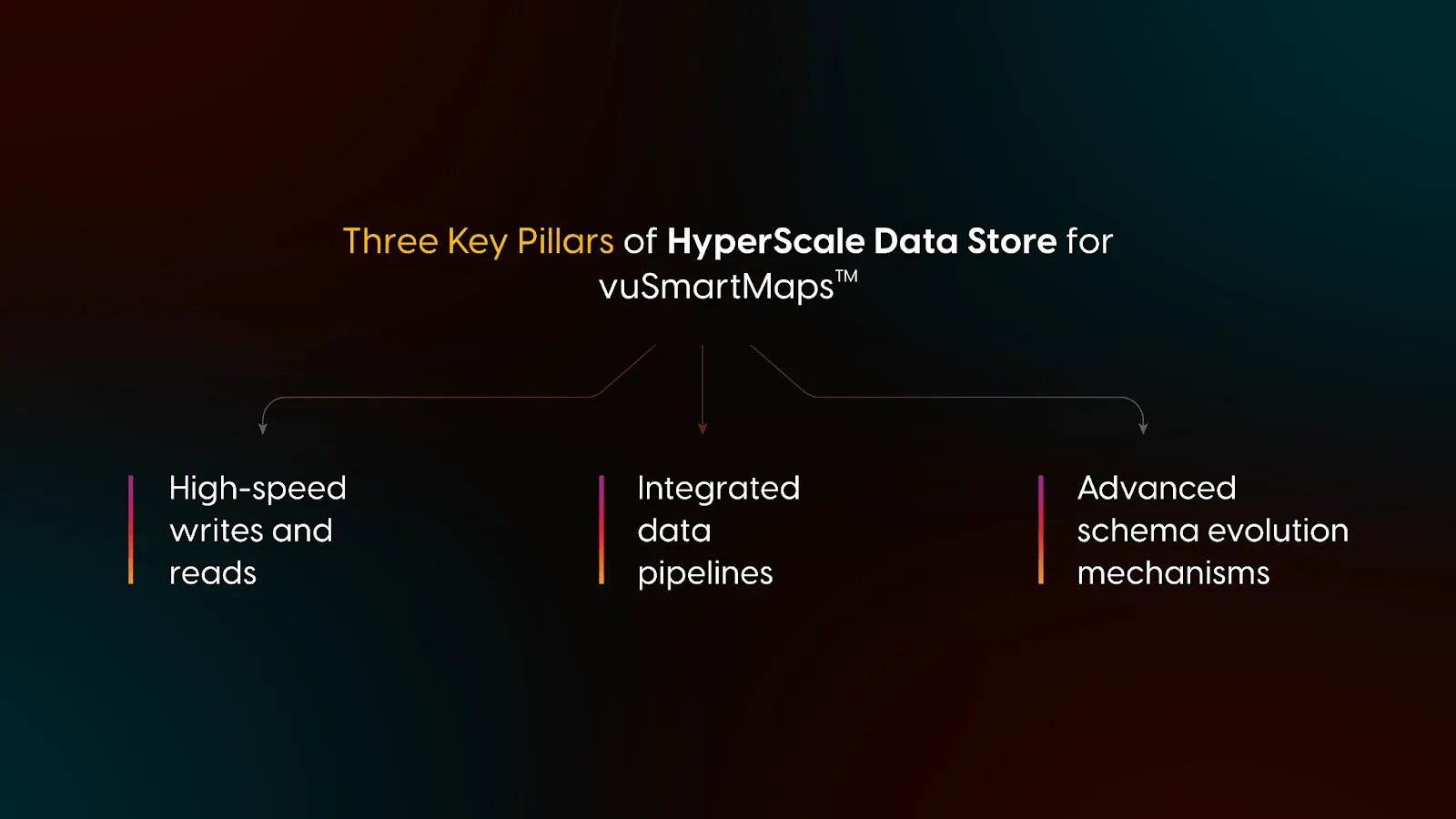
Fig: Three Key Pillars of HyperScale Data Store
Data Tiers and Storage Efficiency
The HyperScale Data store comes with a very efficient storage layer - one of the key levers that the data store provides is compression techniques that can be fine-tuned even at the column level to leverage the properties of the columns. Typically logs compression tops 90-95% in most scenarios thereby reducing 1 TB of logs to just 50-100GB. For high cardinality metrics along with a large number of ID fields and category fields, the typical compression tops 80-85%.The data store can work with a wide variety of disk speeds and can be used to manage multiple data tiers including hot and warm. For warm data, the data store can host its tables in on-premise parquet stores as well as cloud-based stores like AWS S3 and Azure Blobs. This flexibility ensures cloud compatibility and optimizes long-term storage costs. Additionally, this allows for immediate data analytics access of long-term data on dashboards, eliminating the delays typically associated with archival and retrieval processes. This feature enhances both cost efficiency and analytical responsiveness.The data store includes a powerful data roll-up facility that works in real-time to create summarized tables with continuous aggregates for intervals like quarter-hours, hourly and daily.
Scaling and High Availability
HyperScale DataStore is scalable vertically and horizontally. All typical low and medium-scale observability deployments can scale vertically to achieve typical read and write speeds. For example, an 8-core, 32 GB memory system can handle APM data for 100K EPS of data ingestion.The data store can be horizontally scaled with the built-in clustering and sharding mechanism. We have benchmarked the store for cases where 100+ nodes are present in the cluster.For high availability of data store leverage, replicas-based distribution of data across nodes in the cluster is used. VuNet suggests a 1:1 replica for standard deployments.Both vertical and horizontal scaling are extremely easy to achieve in deployments with the system auto adapting to the increased capacity.
Data Exploration and Management
Data exploration on HyperScale DataStore is supported through a SQL interface as well as VuNet’s DSL (Domain Specific Language). This makes the data access and analytics extremely easy to build new use cases.Additionally, VuNet’s LLM based interface, VED, enables natural language based interaction with HyperScale Data Store to explore data and create visualizations and dashboards.vuSmartMaps platform comes with a management user interface to manage data tiers and data management in the HyperScale Data Store.The Data Store can function seamlessly in on-premise installations as well as cloud installations. The deployment and management of the data store are fully integrated into the vuSite Manager layer of vuSmartMaps with installations supported for on-premise Kubernetes based installations as well as EKS, AKS or GKE based cloud installations.
Benchmarks
Benefits
With the HyperScale data store deployment of vuSmartMaps platform, the footprint of current deployments are expected to come down by 30% resulting in a proportionate reduction in Total Cost of Ownership.
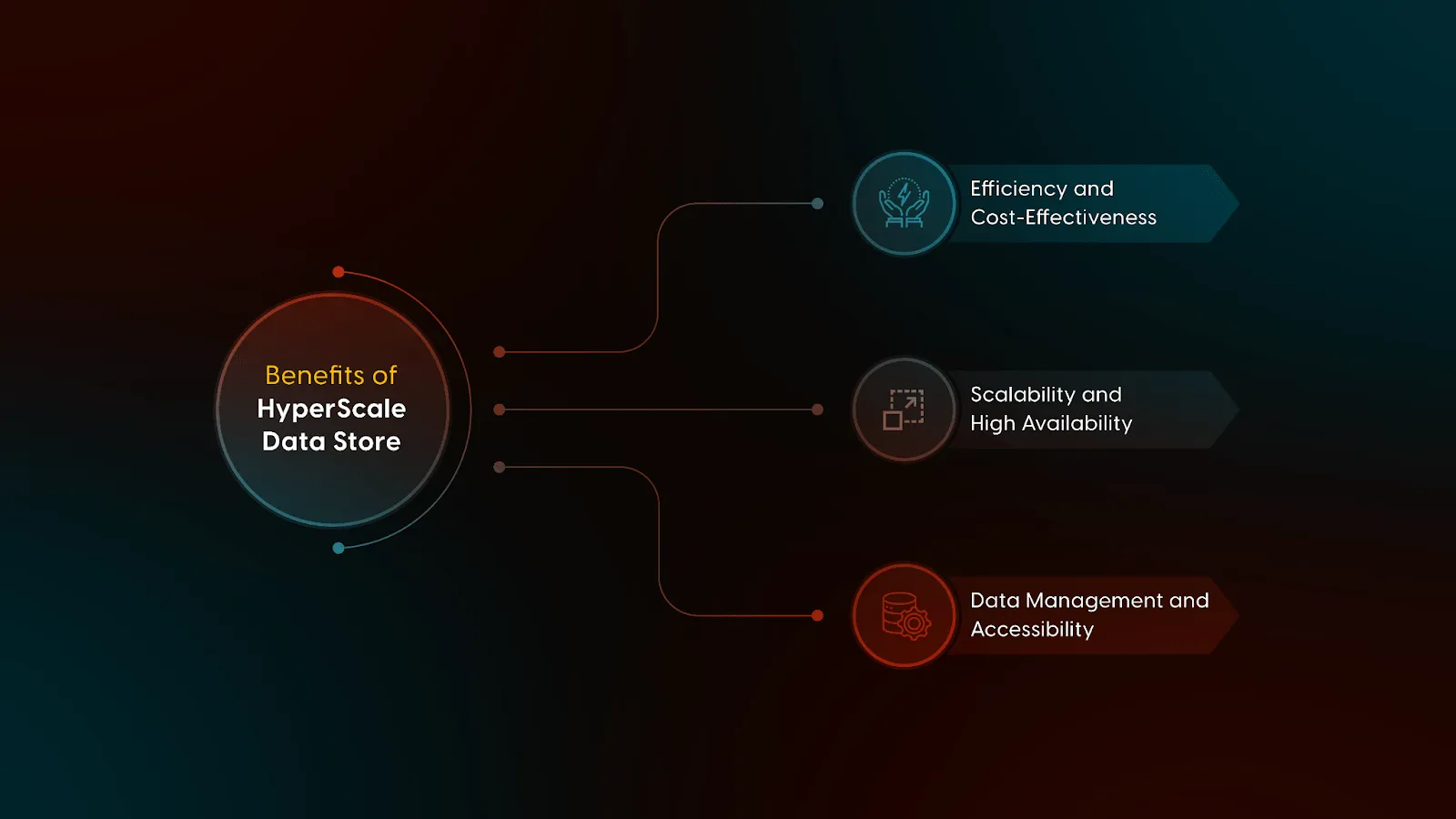
Fig: Benefits of HyperScale Data StoreAt the same time, the new architecture allows the platform to extend the analytics data tenure from the current 30 days to 180 days in the existing deployments. This enables the availability of long-term data analytics reports, historical comparisons and compliance reports. In addition, VuNet's ML and MLOps layers automatically leverage the extended data for achieving higher precision baselining and training to deliver more accurate scores, insights and forecasts.
Summary
The introduction of HyperScale DataStore represents a significant advancement in VuNet’s observability platforms. It is engineered to meet the demanding requirements of high-speed data processing, efficient storage management, and scalable architecture. This development underscores our commitment to technological innovation, aiming to keep pace with the dynamic demands of data analytics in today's fast-evolving landscape. This is just the beginning and stay tuned to know more about the exciting developments and cutting edge work in further database architectures we are constantly working on.

