


All of us have experienced failed online transactions at some point or the other, sometimes even in emergency situations; these irritating experiences often arise from anomalies. Anomalies are undesirable fluctuations in your data that can cause problems in your system, eventually resulting in a bad customer experience. What makes detecting these anomalies so challenging is that anomalies are hard to define in the first place.
Our previous blog post talks more about these troublemakers, highlighting the basic concepts and challenges of anomaly detection, so make sure to go through that before reading further. In this post, we will look at some of the popular anomaly detection systems that are currently in use at various enterprises.
When thinking about monitoring systems, you often deal with data that is a time series, which is just data collected over a period of time. Now, time series data comes in many varieties, and unfortunately there is no singular method that works for all types of this data, even though that would be ideal.
There are many ways of classifying time series data, but for anomaly detection, they can be broadly classified into the six types shown in Figure 1; the anomaly detection method we use depends on the type of time series data that our data falls into.
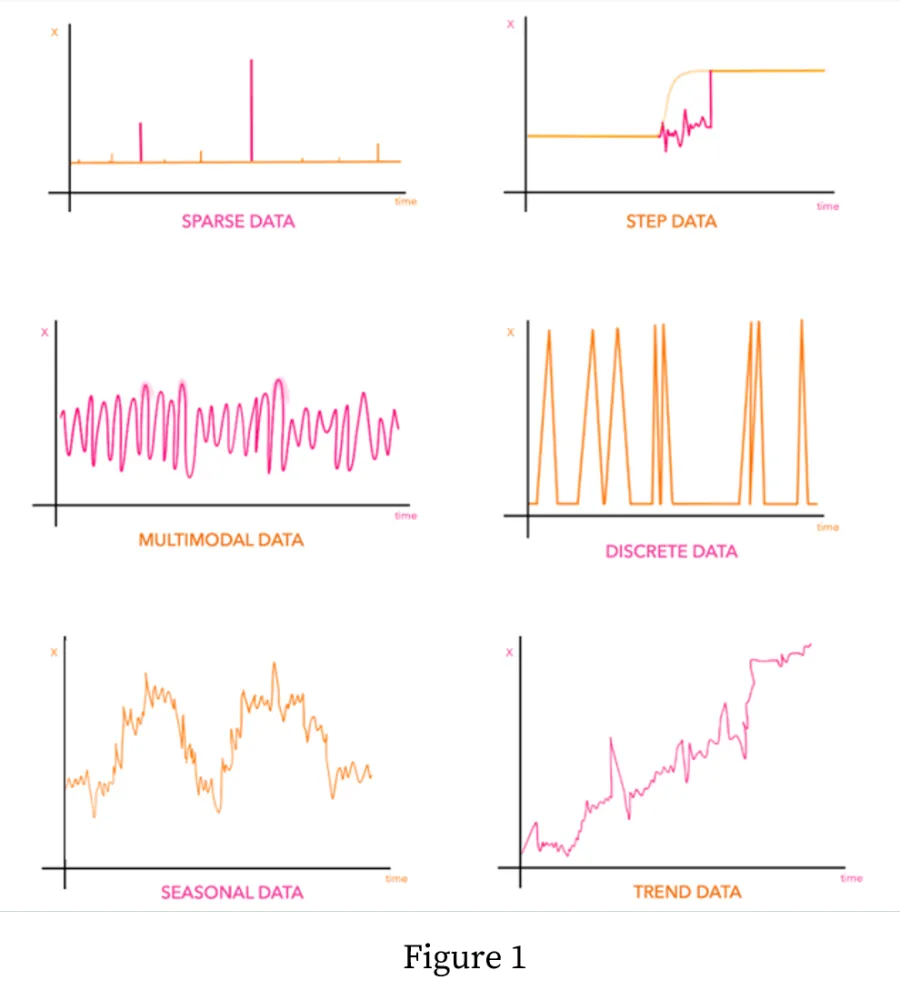
There are several different parameters that we can use to classify a given time series, the two most popular ones are trend and seasonality, as shown in the figure. There are times when time series data show a trend - a steady increase or decrease of something over time- for example, the increase of smartphone purchases since 2005. And a time series becomes seasonal when it has an event that repeats during the same time each calendar year, for example, a rise in the purchase of winter jackets each December.
Now there may only be six types of time series listed here, but there are many more anomaly detection methods, because even for the same type of time series, different methods have different performances. But do not worry! We won’t explore the entire jungle in this blog, just touch upon three of the most popular algorithms.
Naive statistical methods
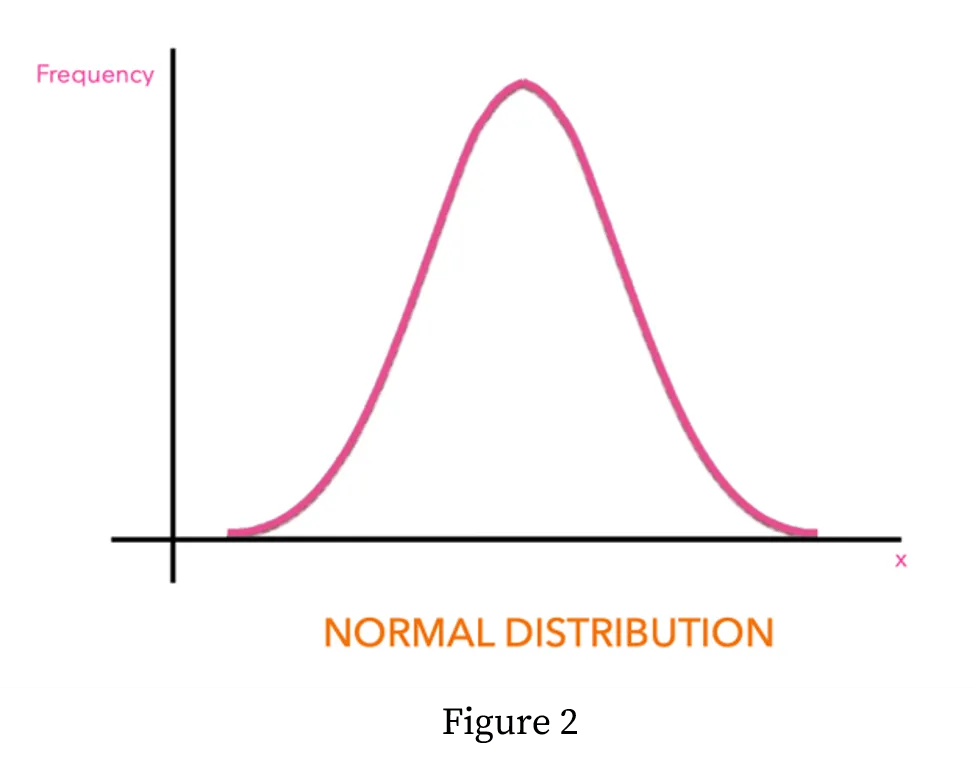
The simplest way to develop an anomaly detection method is to assume that all our data follows a Gaussian distribution - that is, a bell shape as shown in Figure 2. A lot of naturally occurring data follows this kind of distribution, ranging from the velocities of gas molecules in your room to the heights of people around the world. You can see in Figure 2, how the majority of the data points in the time series have values near the centre, and the number of data points decreases as we go towards the two tails of the bell. The idea with such a method is that if we calculate the central value- the mean- of our data, anomalies would normally exist at a specific distance from this mean, in the tails! This does work in many situations, but there are also some problems with this approach. First of all, it’s not necessarily true that our data looks like a bell to begin with. Secondly, even if our data follows the bell curve, our data can consist of outliers, and those are not anomalies. Thirdly, and perhaps most importantly, there might be anomalies well within the bulk of the bell curve!
ARIMA
An acronym for Autoregressive Integrated Moving Average; its full form is just as intimidating as self-explanatory. Without getting into too many technical details, ARIMA belongs to a class of statistical models that uses linear regression to analyse time series data. Linear regression is a model that finds a straight line to fit the pattern of your data, allowing you to make predictions based on your data. A simple, yet powerful technique!
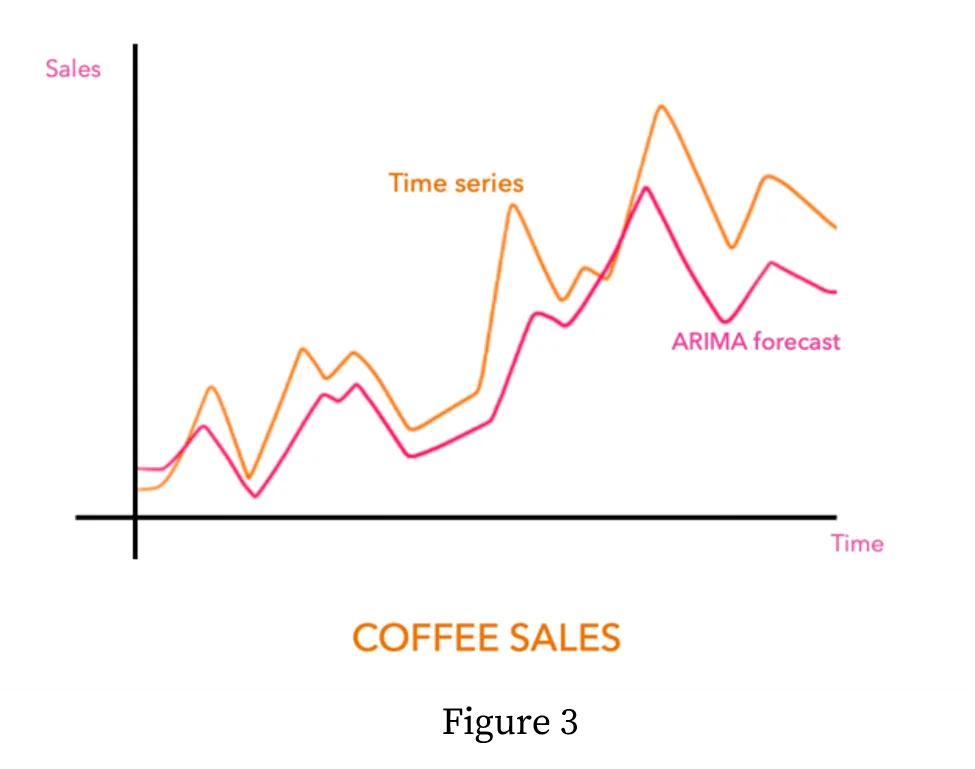
Building on this, autoregression refers to a model that is applied on time-series data, where the data that you make your predictions on consists of multiple previous points in time (aka time steps). Autoregression then uses data from previous time steps to predict an outcome at a future time step. In this manner, it can forecast upcoming events. For example, if your time series data is about a neighborhood’s internet usage over 24 hours of the day, you could use autoregression to forecast what the internet usage will be like in the next hour. And if the internet usage is significantly different from the prediction, you can say that it's an anomaly! Figure 3 gives an illustration of how the forecasting from an ARIMA model can be compared to existing data to identify where anomalies are!
DeepAR
Naive Statistical methods, ARIMA and many such models broadly fall under the category of statistical analysis and signal processing, which have been developed over many decades. Although these methods are very powerful, one important limitation of these methods is that they have parameters which have to be manually tuned to get a desirable performance. In order to address this limitation, the last decade has seen a spectacular rise of various Deep Learning algorithms that make it significantly easier to tune these parameters.
The DeepAR model developed by Amazon is one such Deep Learning algorithm that also performs forecasting on time series data by capturing the underlying patterns in the time-series. However, unlike ARIMA, it is not just based on simple statistical methods but uses an advanced form of neural networks called the Recurrent Neural Networks (RNN). Neural networks are inspired by the human brain, and use a network like structure to solve any given problem. They can handle a very wide variety of data, but the RNN model works really well with sequential data like a time series. As a consequence, models like DeepAR can provide a much more accurate forecast of the time series data you investigate, and are likely to be able to delineate more nuanced patterns in the data, allowing you to catch anomalies more accurately!
Ultimately, there is no magic algorithm that works for all kinds of time series, so the anomaly detection algorithms deployed by VuNet use a combination of all these various methods. Even the most advanced Deep Learning algorithms have their own limitations, and even when they work well, can often be much slower than other simpler methods based on statistical and signal processing techniques. At VuNet, we have carefully designed a robust ensemble of algorithms that can automatically find out which algorithm is best suited for a given time series, thereby helping our enterprise customers in detecting anomalies in their time series data with a very high accuracy.
So, this blog has taken you through the most popular algorithms used for anomaly detection and some insights into the anomaly detection algorithms deployed by VuNet, which has been near perfected with deep research and experience.
Now that with our series of blogs, you would have an understanding of anomalies and the various methods to detect anomalies, in our next blog, we will bring to you the different types of anomalies which is important to understand, for better analysis and RCA.
VuNet Systems is a deep tech AIOPs startup revolutionizing digital transactions. VuNet's platform vuSmartMaps™, is a next generation full stack deep observability product built using big data and ML models in innovative ways for monitoring and analytics of business journeys to provide superior customer experience. Monitoring more than 3 billion transactions per month, VuNet's platform is improving digital payment experience and accelerating digital transformation initiatives across BFSI, FinTechs, Payment Gateways and other verticals.

