


VuNet’s vuSmartMaps™ stack introduces a domain context to observability and augments business journey to transaction metrics traceability across the stack of distributed systems in a digital-first world.
About this series: The Intelligent Observability blogs aim to elaborate upon the drivers of observability in modern complex systems, and how organizations can make the gradual transition to complete automation in their enterprises. You can find part 1 of the blog here, and part 2 here.
IT Operations teams have traditionally grappled with two critical parameters in the enterprises they monitor – MTTD (Mean Time to Detect) and MTTR (Mean Time to Resolve) for an issue. As observability data gets more voluminous and convoluted, and systems get more and more interconnected, complex and difficult to monitor, both these parameters are adversely affected.
MTTD is dictated by the volume of logs and metrics with alerts/anomalies that IT Operations and Site Reliability Engineers (SREs) need to comb through, and MTTR depends on the number of alerts that these teams can correlate by looking through log files and transaction traces to arrive at possible root causes for an issue. These issues can originate either internally in the enterprise’s own infrastructure, or externally in one of the many microservices and APIs a transaction converses with. An added layer of complexity originates from the fact that errors could be business or technical in nature.
In the first two blogs of our Observability Series, we introduced the concept of Business Journey Observability, and how VuNet’s patented 5C approach to introduce a domain-centric context into transactions creates a rich, robust and scalable platform called vuSmartMaps ™. This platform provides an information architecture that lends itself to more sophisticated AI algorithms and Machine Learning (ML) models built upon it, to ensure that an enterprise can take that final step towards automation: the adoption of AIOps for anomaly detection and intelligent root cause analysis (RCA), as well as automated remediation of issues in the enterprise.

vuCoreML – Enabling AIOps in Business Journey Observability
Our blog on pre-built models being a must for AIOps platforms used an interesting analogy for ML algorithms, derived from Pedro Domingos’ book “The Master Algorithm”. Using farming as a metaphor, he states, “Learning algorithms (ML algorithms) are the seeds, data is the soil, and the learned programs are the grown plants. The machine-learning expert is like a farmer, sowing the seeds, irrigating and fertilizing the soil, and keeping an eye on the health of the crop but otherwise staying out of the way”.
With the wealth of observability data and business context at our disposal via vuSmartMaps™, we can put this analogy into practice and have the required AIOps programs flourishing in an enterprise in no time! MLOps (Machine Learning for Operations) is about applying ML algorithms on the operations data lake built through the data pipeline by streamlining the modelling lifecycle. That is the core objective of vuCoreML – an infrastructure for building ML models on the vuSmartMaps™ platform’s data architecture.
For any ML model to work, there are 2 stages involved – training and deployment. The training phase, (based on auto-regressive or semi-supervised techniques), requires a relatively large amount of historical data to work with. Based on this, the model extrapolates patterns, detects trends and learns to come up with insights, some of them predictive in nature. The deployment phase requires the model to be actively deployed in a streaming data pipeline, so the model can detect these trends and patterns in “live” data. An optional, but important stage is the feedback loop, where human- or machine-generated inputs on the efficacy of the model and the quality of insights it generates, are fed back to the model to fine-tune it.
Keeping the above analogy and workflow in mind, this is how we can visualize the application of vuCoreML approaches to the information architecture in vuSmartMaps™:
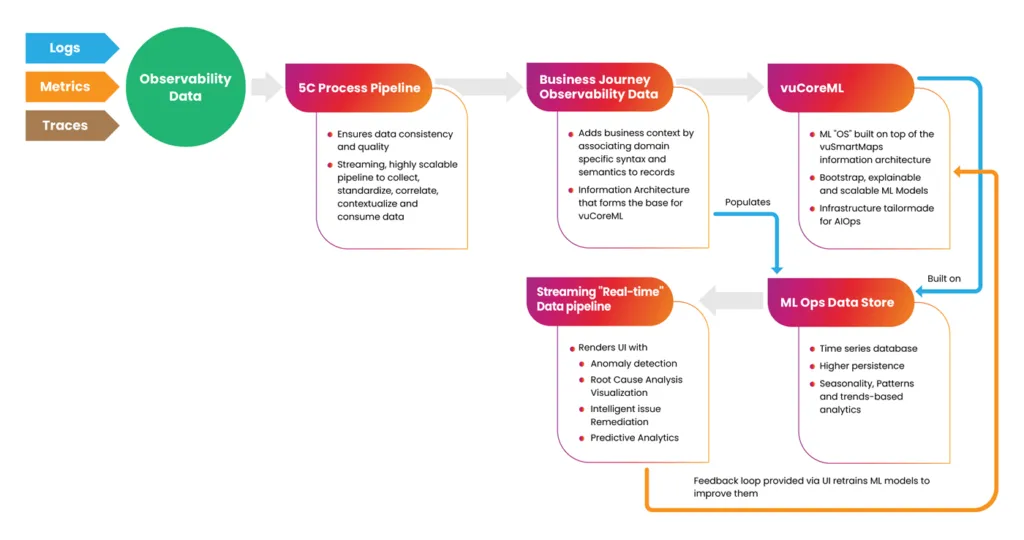
Fig: vuCoreML approach on vuSmartMaps™ allows the creation of tailormade ML models and AI algorithms for introducing automation in the enterprise.
ML Models required in vuCoreML
How do we decide upon the models that need to be built on vuCoreML?
Our blog on pre-built models being a must for AIOps platforms detailed the results of a survey conducted by AIOps Exchange, a not-for-profit private forum. The participants were 100 IT executives representing large enterprise organizations as well as IT industry analysts and academics. The survey revealed that 26% participants deal with 50 or more monitoring tools in their enterprise, while 40% organizations are flooded with 1 million plus events every day.
The key asks of the participants were summarized as follows:
- Automated Root-Cause Analysis (RCA) (45%)
- Anomaly detection (20%)
- Self-healing capability for routine issues (20%)
- Intelligent alerting (8%)
In short, the participants were most concerned about minimizing MTTD and MTTR, and averting downtime wherever possible. Given the volume of the business observability data collected, and the complexity of the environment it is collected from, it follows as a corollary that the only way to achieve these objectives is through the adoption of AIOps as soon as possible.
Enter vuCoreML
The below diagram shows how vuCoreML has been conceptualized in order to enable quick adoption of AIOps in an enterprise:
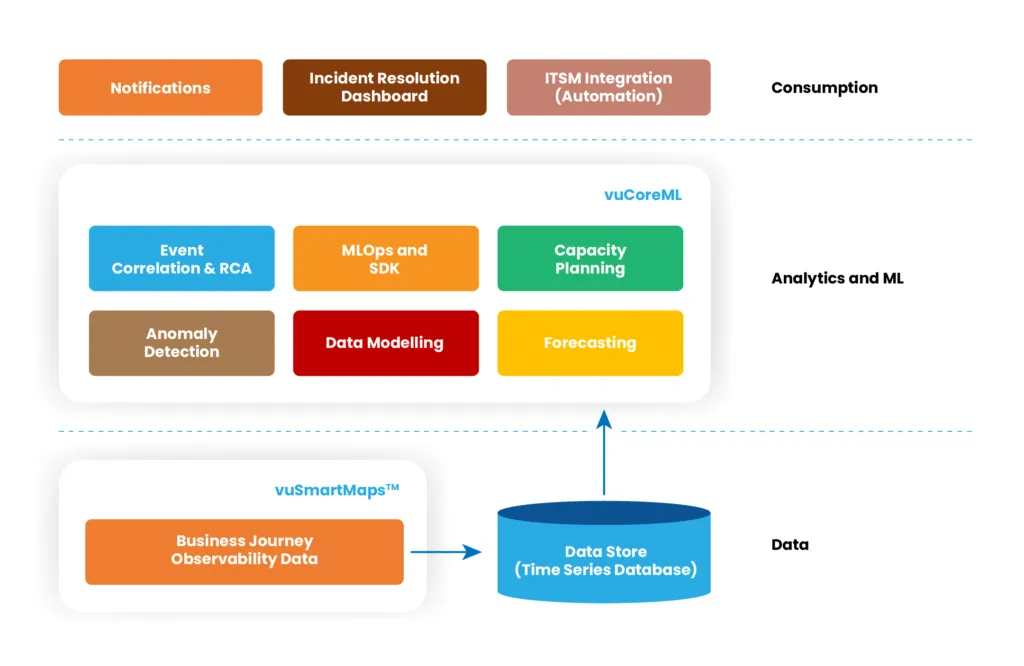
Fig: vuCoreML has pre-built ML models for enabling AIOps in the enterprise
Anomaly Detection Models
These enable enterprises to move away from traditional static alert-based dashboards to intelligent anomaly detection, which significantly reduces Mean Time to Detect (MTTD). Traditionally, IT Operations teams had to contend with alert storms, with alerts raised via static thresholds on various operational metrics. These alerts also contained false positives, which made issue detection a manual and mentally draining process. With AI-based anomaly detection, ML models look at seasonality, trends and patterns in data over time and detect anomalies i.e., abnormal behavior. VuNet’s approach to anomaly detection consists of online time series classification to identify the signature/behavior of time series data, and dynamically deciding on techniques to use, like deep learning models as well as statistical models, that can scale to thousands of signals and dimensions. vuCoreML reduces the number of alerts that IT systems generate on a daily basis by bubbling up important alerts and reducing noise through ML algorithms. This reduces alert fatigue among IT Operations and SRE teams.
Event Correlation Models
Not only do our ML models detect anomalies faster and more accurately, but they also perform the onerous task of correlating these anomalies using a vu3T correlation framework, which is based on time, transaction IDs or transaction topology. This means related anomalies are clubbed together and presented in the context of a single issue, affecting a set of transactions, services or happening in a particular time frame. This eliminates the need for manual correlation, saving a significant amount of time and effort.
Intelligent Root Cause Analysis
While Anomaly Detection and Event correlation leads to lowered MTTD, another parameter that needs to be optimized is the MTTR (Mean time to Resolve). Root cause analysis in heterogeneous systems is a complex and time-consuming task. Finding that single infrastructure element, external API/microservice, network switch, storage device or transaction parameter that is leading to the IT error or business error, is akin to finding a needle in a haystack. This is where event correlation and causality analysis help. With vuCoreML, the event correlation employed is taken a step further by taking a hierarchical approach to capture the most likely root causes, thereby decreasing the MTTR.
Automated Issue Remediation (Self-Healing)
Enterprises are looking for tools providing automatic issue remediation or self-healing capabilities, given the regulatory penalties, loss of revenue and dip in customer satisfaction that stems from downtime. Organizations typically have ITSM (IT Service Management) tools and processes to deal with incident management. Automatic creation of incident tickets, routing them to the appropriate teams, running scripts to address issues in cloud infrastructure, like bringing up additional service instances or killing a process eating into CPU utilization – are all ways and means to automatically resolve incidents when possible, and minimize or eliminate downtime entirely.
We will explore each of these use cases in further detail, along with tailor-made tools in VuNet’s arsenal that address these requirements, in our upcoming AIOps series of blogs. Do keep reading, and let us know how VuNet can help your enterprise transform its operations via AI/ML, by reaching out to us at info@vunetsystems.com.

