


A few months ago, we introduced Ved AI, our GenAI copilot, as part of a broader initiative to redefine Business Journey Observability with cutting-edge large language model (LLM) frameworks. The primary objective of Ved AI was to use LLMs to offer a unified approach to data understanding across heterogeneous data types—logs, metrics, traces—while expanding the context further by ingesting data from the platform, system documentation, and even historical incident reports.As part of these ongoing efforts to continuously expand the knowledge base and use cases, we are excited to announce a new module: Ved AI for Documentation.https://www.youtube.com/watch?v=UA08czdECPUVed AI for Documentation is an extension of our Ved LLM framework, specifically crafted to improve how users interact with our vuSmartMaps™ platform. By integrating Ved into our platform documentation, we aim to significantly reduce the friction often associated with learning and using real-time big data/ML observability platforms, enabling users to seamlessly configure data pipelines, models, and alerts with minimal effort.Our customers have always relied heavily on our documentation, but we’ve consistently heard feedback about the challenges of finding the “right information at the right time.” Ved AI for Documentation directly addresses this by using advanced retrieval-augmented generation (RAG) techniques to understand the intent and context of user queries, delivering tailored responses that go beyond simple keyword searches.This innovative approach not only improves the efficiency of information retrieval but also allows users to engage with the documentation in the flow of their work, providing contextual answers that help them complete tasks quickly and accurately. Ved AI for Documentation is now live and ready to enhance your experience with vuSmartMaps™, making your journey with our platform smoother and more productive. This helps us address these challenges head-on, making information retrieval for our users faster and more intuitive, as they spend less time searching, browsing, and perusing through our documentation.
Understanding Ved AI for Documentation
Ved AI transforms the documentation experience by integrating an expanded knowledge base that includes all product-related documentation. We are also streamlining our internal processes to ensure that new documents are added to Ved’s knowledge base, making them readily accessible to users.Ved AI for Documentation utilizes the Retrieval-Augmented Generation (RAG) framework, where the entire documentation is broken down into small, manageable chunks and stored in a vector database.
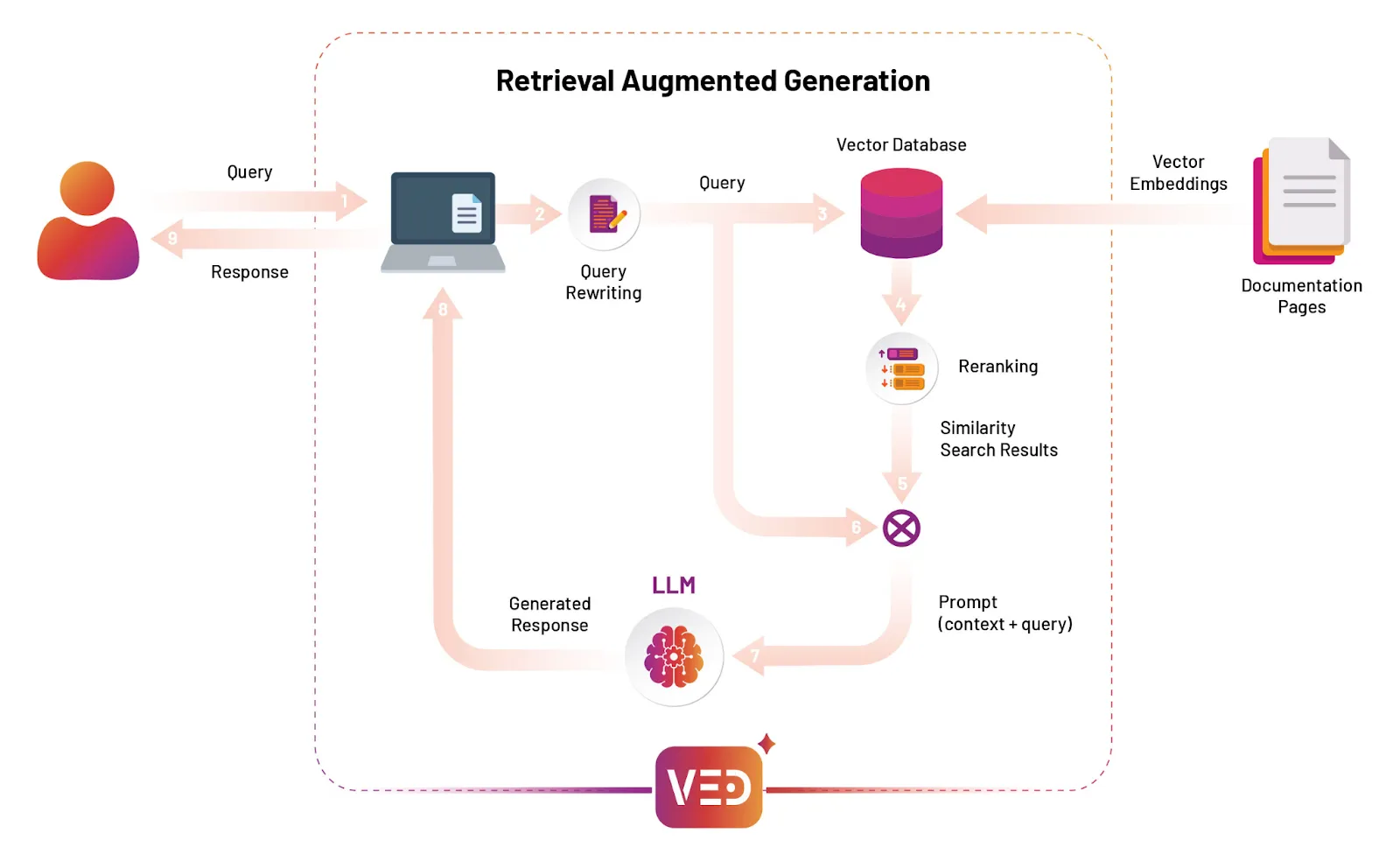
Fig: Architecture - The Journey of a Query and Response in Ved AI for DocumentationIn comparison to a conventional document search, where queries are made to a document store in the form of keywords, the focus here is on understanding the intent and context of a query to deliver a tailored response.
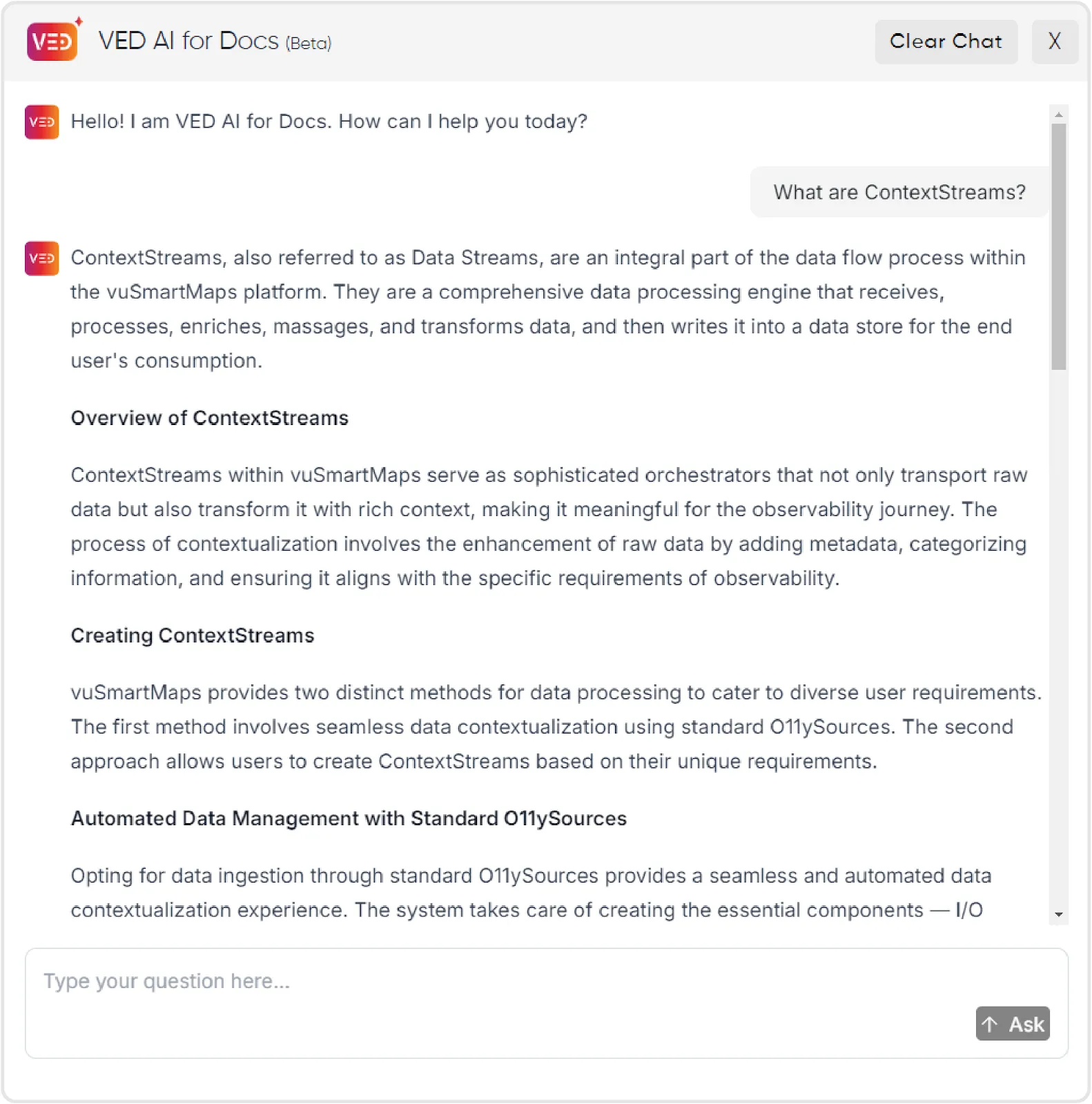
Fig: Ved AI for Documentation responds on specific features within vuSmartMaps™
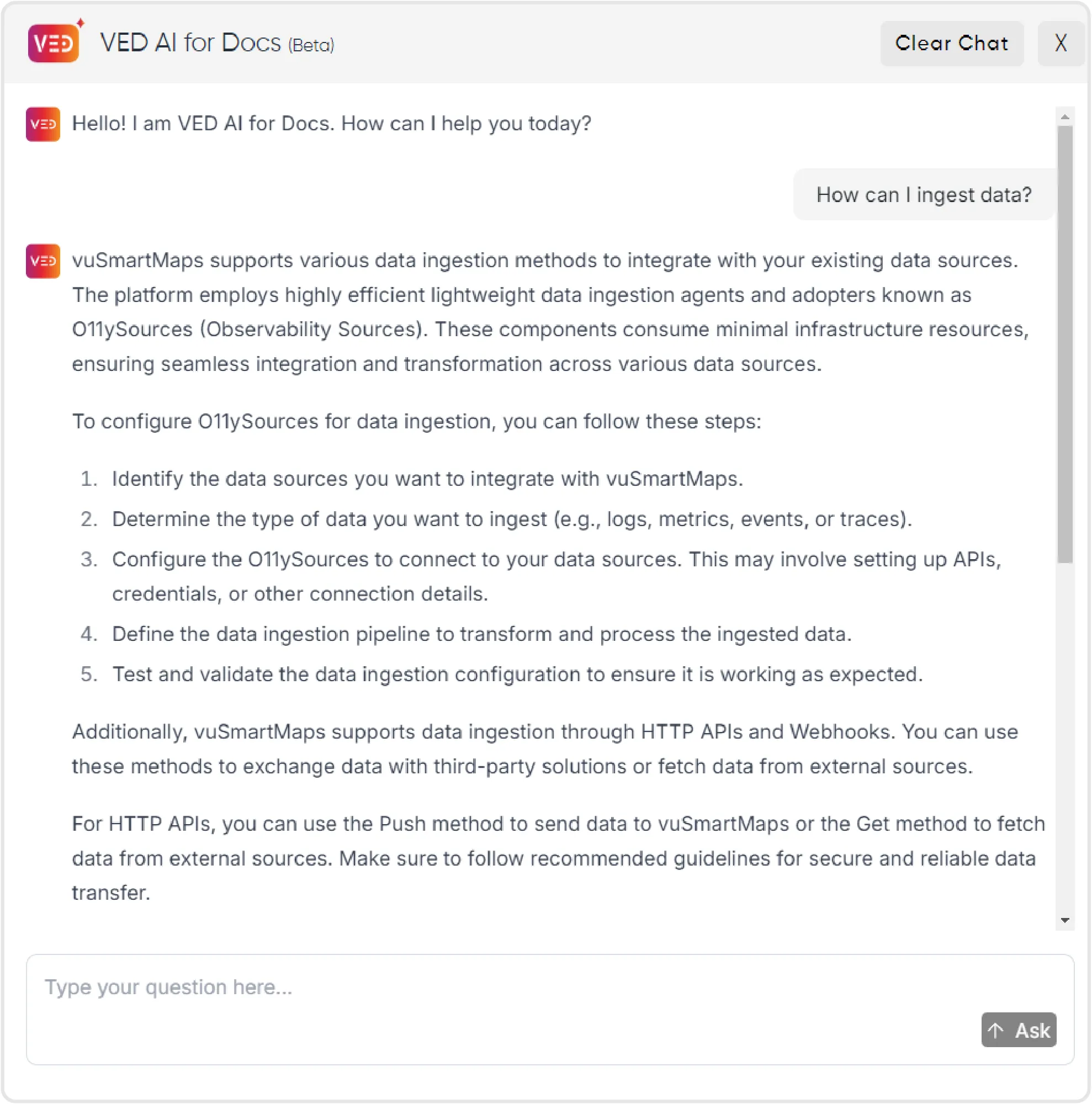
Fig: Ved AI for Documentation responds to contextual queries like “How, Why, Where, " beyond “What?
Enhancing User Experience: How Ved AI Delivers Accurate and Contextual Responses
To ensure that Ved AI consistently delivers accurate and context-aware responses, we have focused on continuously refining our underlying mechanisms. This includes implementing advanced techniques like query rewriting, dynamic conversations, and similarity search. These approaches work together to ensure that users receive the most relevant information at the right time. We keep evolving these mechanisms through beta testing and user feedback and we have many more in the pipeline and roadmap to achieve even more grounding of results.
Query Rewriting
Users often tend to ask short questions which can be ambiguous at times. To provide a useful and tailored response to the user's query we resorted to query rewriting. We enrich and add context to the user's query to get a useful response in return. Below examples show how the input queries are re-written before the similarity search.
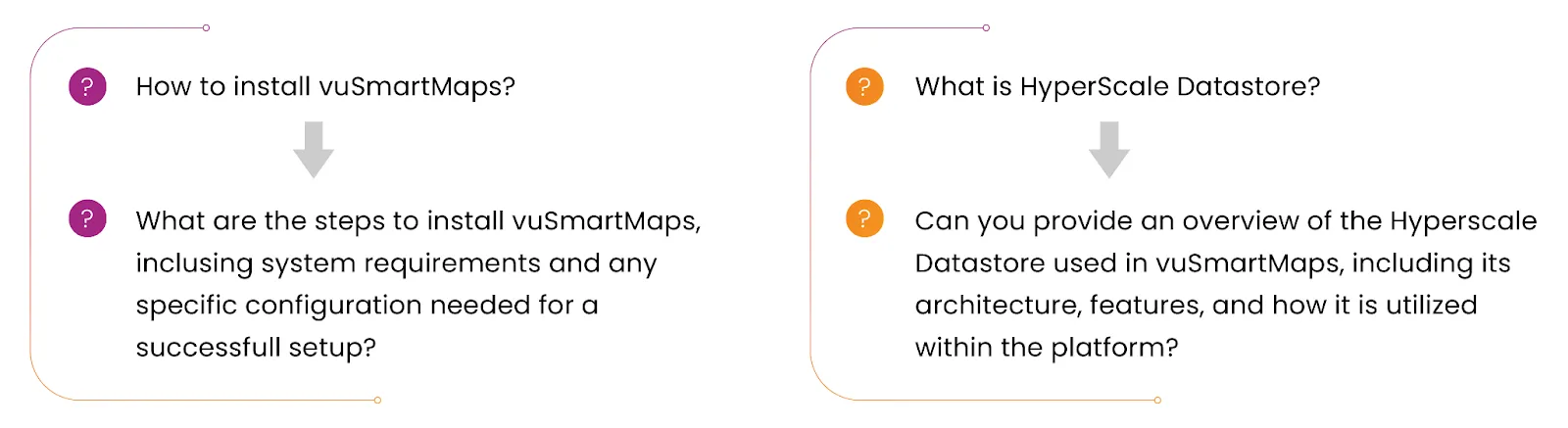
Fig: Prompt Engineering for Query Rewriting
Building Conversations
Ved AI for Documentation doesn’t just respond to individual queries—it engages in a dynamic conversation by understanding the context of previous queries. This ensures continuity and coherence in every interaction.
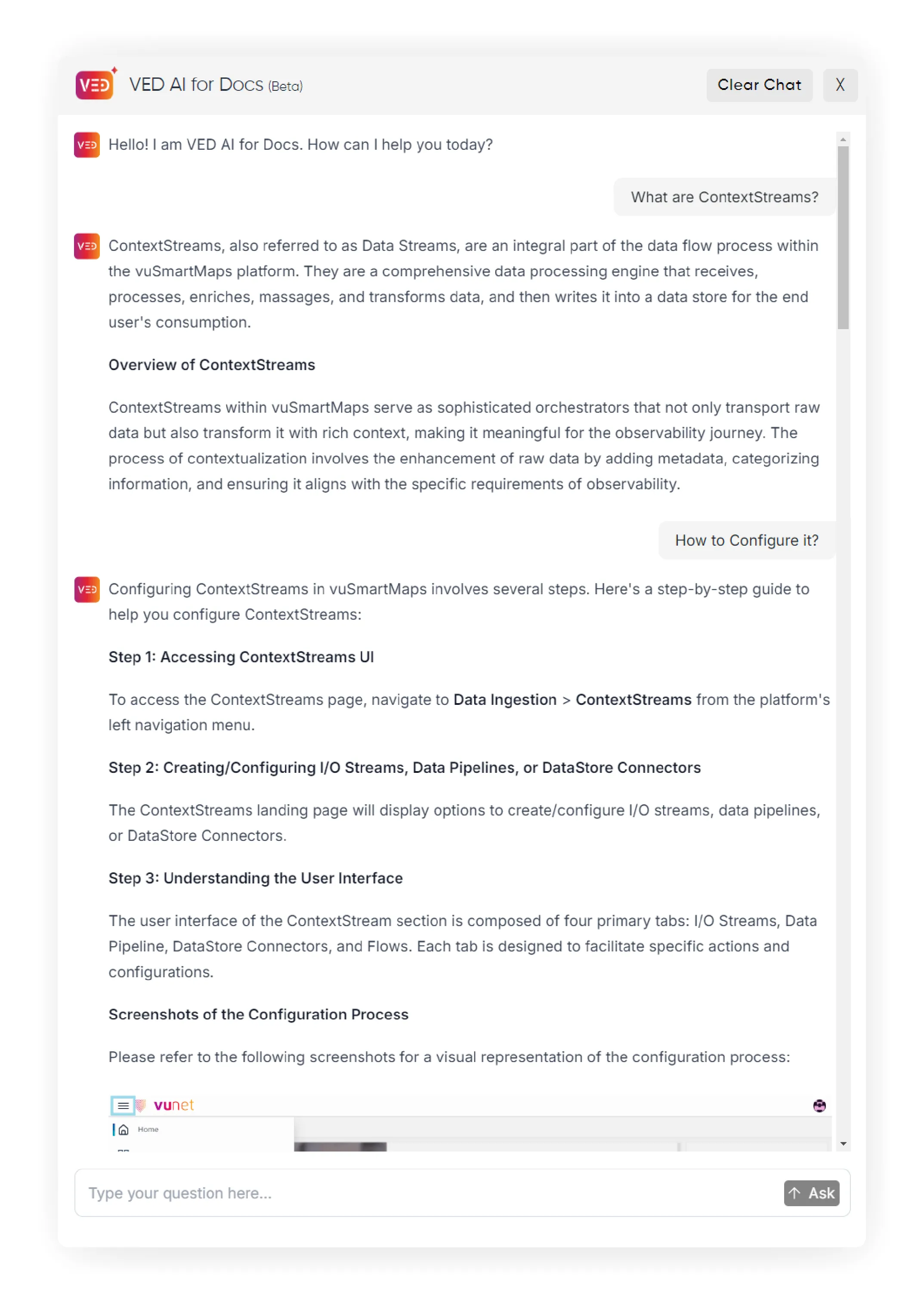
Fig: Contextual Conversations
Similarity Search and Reranking
Similarity search is the key step in a RAG system. This involves turning the user’s query into a high-dimensional vector and finding the nearest vectors in a vector database, where each chunk of our document is also represented as a high-dimensional vector. The vector database returns a desired number of document chunks stored in the knowledge base that is nearest to the query vector. Imagine plotting these vectors on a 2-dimensional graph for simplicity, even though the actual process involves hundreds or thousands of dimensions. In this simplified plot, you can see how vector search works in a 2-dimensional space.
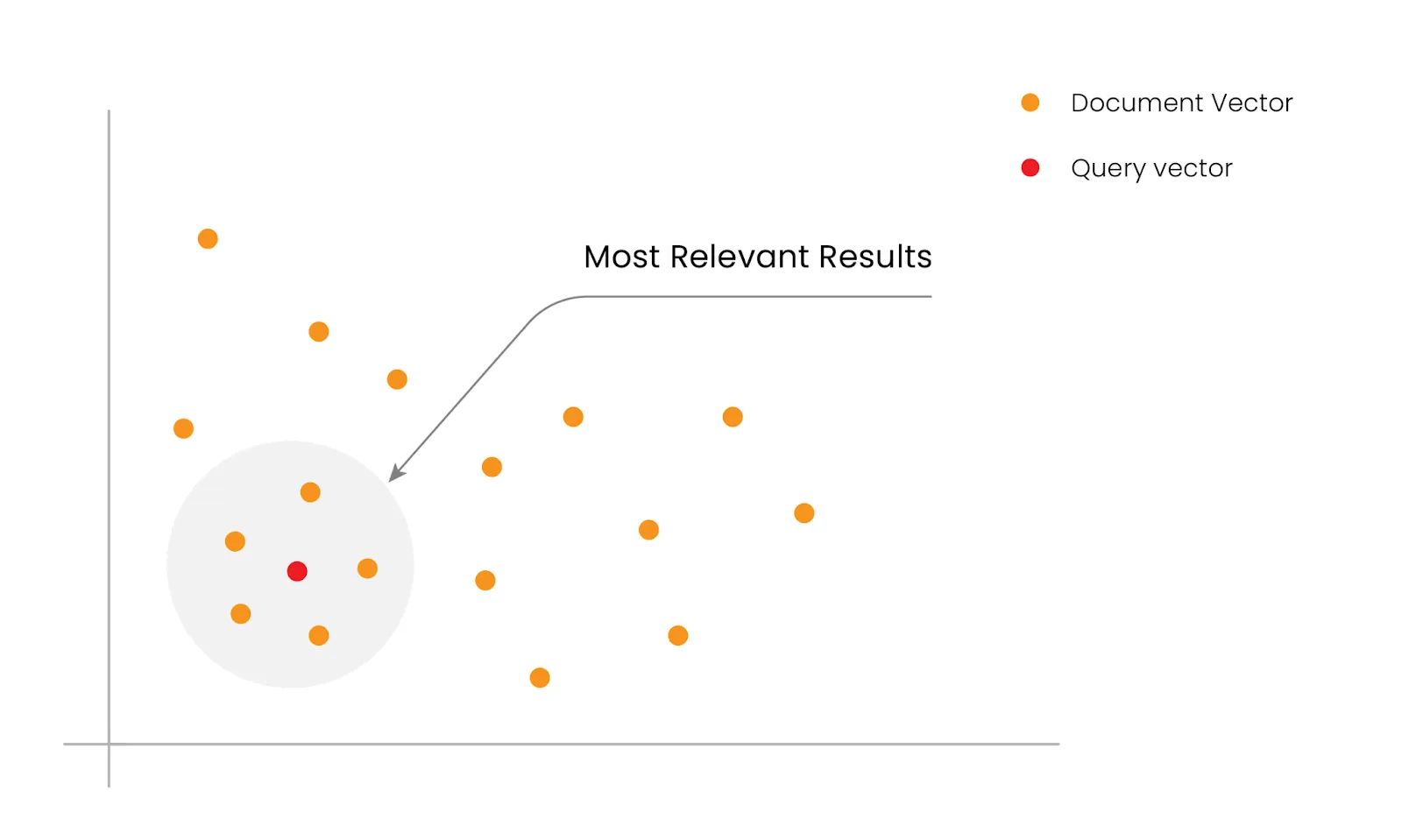
Fig: Demonstrating Vector Search in a 2D GraphThis method is much better than traditional keyword-based search because it understands subtle meanings and context, leading to more accurate and relevant information retrieval.The LLMs take the similarity search results along with the original query as an input to provide a tailored response to the user query. In a pursuit to deliver quality responses, we rerank the results by calculating the relevance score between the original query and the corresponding documents using a re-ranker model.
Insights from our Beta Experiments
In the past few months, we tested Ved AI for Documentation in several customer environments and with our Customer Solution Group team. We analyzed over 1,000 queries, on 150+ documents, and the responses have not only enhanced our documentation quality but also provided valuable feedback to our product team.Our internal quality score for Ved AI for Documentation has improved by 12% since its launch, reflecting a steady improvement in the quality of our responses. We were able to achieve this improvement with constant refining of the system with techniques like query rewriting, reranking, and prompt engineering. We are constantly working to improve the quality of Ved further to make it more useful.This iterative process is enhancing the overall ease of use of our platform and has helped reduce our user training efforts by about 20%.
Looking Forward
We are continuously working to reduce the friction users experience when navigating our platform, and Ved AI is a significant step in this direction. Our roadmap includes several key enhancements aimed at further improving the user experience with Ved AI:
- Enhanced Contextual Understanding: We are refining Ved’s ability to understand and respond to more complex queries, ensuring users receive even more accurate and relevant information.
- Real-Time Document Updates: We plan to automate updates to Ved’s knowledge base in real-time, allowing for instant reflection of changes in our documentation, and ensuring users always have access to the latest information.
- Improved Multi-Language Support: We are also planning to introduce multi-language support, enabling a broader range of users to interact with Ved AI in their preferred language.
With these enhancements, Ved will bridge the gap between our comprehensive documentation and users' need for quick, efficient access to it. This will enable users to rapidly transition from setup to actively monitoring and managing their infrastructure, which is at the heart of our platform’s value proposition. This shift from spending time on platform setup to achieving unified observability allows users to focus on actions that directly impact their business operations.
Try Ved AI for Documentation Today
Ved AI for Documentation is now live on our online documentation. We invite you to explore it and enhance your experience with the vuSmartMaps™ platform.

